
Limits of linear learning
Neural implementation of linear classification and principal components analysis

After sensing and coding, the brain must reformat information for behavior in the world. For example, to act on an object, the number of photons hitting each rod, or the decorrelated activity across photoreceptors is probably not that relevant. The brain may, however, need to know how close the object is, or which direction it’s moving. Information is reformatted into representations1 that make relevant variables explicit.
In the mammalian brain, we know that primary visual cortex (V1) represents low-level features such as localized oriented edges. But to forage for food, or identify the face of a friend in a crowd, more abstract and complex concepts are needed. How are these representations formed, and how can we understand what they are? If we were to build a brain, what would we put in each box in the cortical diagram below?

We are very far from answering these questions, but they serve as high-level motivation for this post and the next. I’ll describe several learning rules that can be implemented by basic neuron models, their resulting representations, and their limitations.
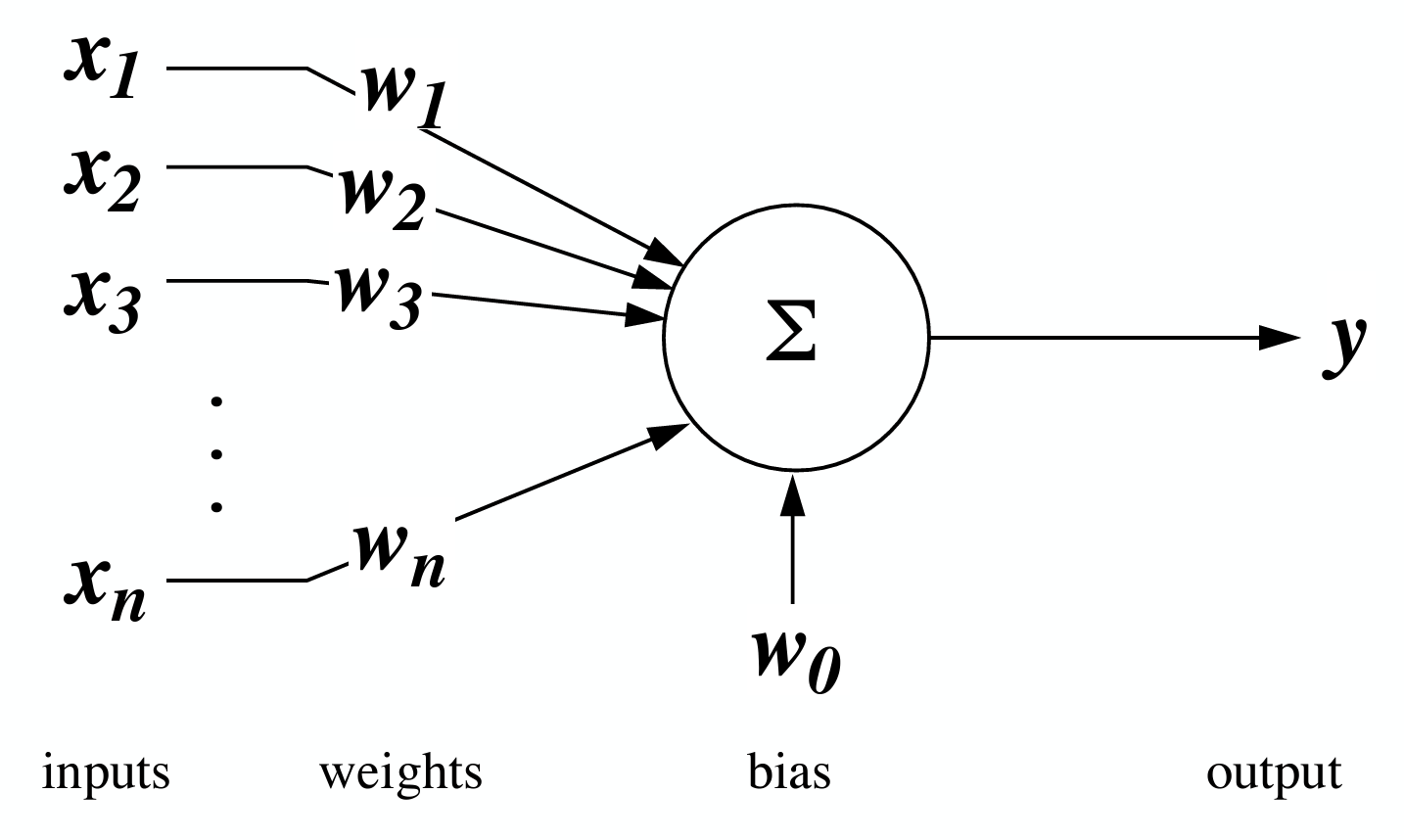
Rather than tackling the entire problem of visual perception, we’ll start small, with the model that Bruno says “is ironically still with us today”: the perceptron, designed for pattern recognition2 by Frank Rosenblatt in the late 1950s. Why ironic? We spent a few lectures talking about the ways in which neurons are not linear, but the perceptron is fundamentally a linear summing device that takes inputs from other units, multiplies them by some weights, and adds them together. The effectiveness of the perceptron unit lies in outputting a nonlinear function of that sum, which crudely approximates an action potential. This model is also the building block of all current machine learning, so there are a million tutorials and historical accounts out there. I’ll just focus on its limitations.

There’s actually nothing we can say about the limitations of the perceptron that hasn’t already been said. Marvin Minsky and Seymour Papert basically wrote an entire diss track in 1969. But for our purposes, perceptrons have two major weaknesses. First, they require labels, or a teaching signal, to learn the weights mentioned above. We call this a supervised learning problem. For example, if you want to train a model to identify objects in a supervised fashion, you must know the true identity of each example in the training set. Is it reasonable to assume that for any problem we want to solve, in machine learning or in nature, we have explicit ground truth information for every example? Probably not. Second, while the perceptron has nice formal guarantees for labelled data that are linearly separable, these don’t hold for non-linearly separable problems (of course, you can transform your data into a space where it is linearly separable). In the above right figure, imagine if you had a + point to the right of the - points; as this dataset is not linearly separable, you would not be able to find a single line in 2D to separate all + from all -. Unfortunately, pretty much all the problems we care about do not have labels, and are not linearly separable. Very sad!
Even with all its issues, the perceptron is a good starting point because it sets up the problem of learning, or how to find the best representation for a task. Given a set of points and labels, how do we arrive at the correct w? It turns out it’s just basic calculus: assign some kind of differentiable score function to the model, and change w iteratively such that it increases the score. Gradient descent is still the most effective learning algorithm in practice today. There are also a million tutorials on this, so I won’t go into it here.
Other than the tenuous connection between a perceptron and a real neuron, how does this all relate to the brain? Is there a “teaching signal” that helps us modify our synaptic weights? Is gradient descent implemented in the brain3? Up until this point in the course, most concepts have been grounded in physiology or experimental evidence: biophysics, spiking neuron models, sensory and efficient coding. We are about halfway through (I am a few weeks behind with blogging), and the topic of representations marks the start of the more theoretical section of the course. That is, what are possible models and theories that could explain phenomena in the brain, based on mathematical ideas we may not yet have experimental proof for? These theories can then drive future predictions and experiments.
There is also clearly a big overlap between theoretical neuroscience, machine learning, and computer science, which is not coincidental: neuroscience, cybernetics, and computation have been intertwined since their beginnings. And the first well-known linear(ish) neuron model was not actually the perceptron, but the 1943 McCulloch-Pitts neuron, which also inspired early computers4.
I’m rambling, but there is so much to say! We are also rapidly approaching my research area, so I have to restrain myself. Let’s examine other types of lesser-known early models beyond the perceptron, starting with an unsupervised learning method, which does not rely on ground truth labels. Principal components analysis (PCA), which decorrelates data, is one such method. Below, the original data contain correlations: as x values increase, so do y, and vice versa. After linear projection onto the orthonormal basis W, or the directions of highest variance of the data, the decorrelated data on the right no longer have this pattern.
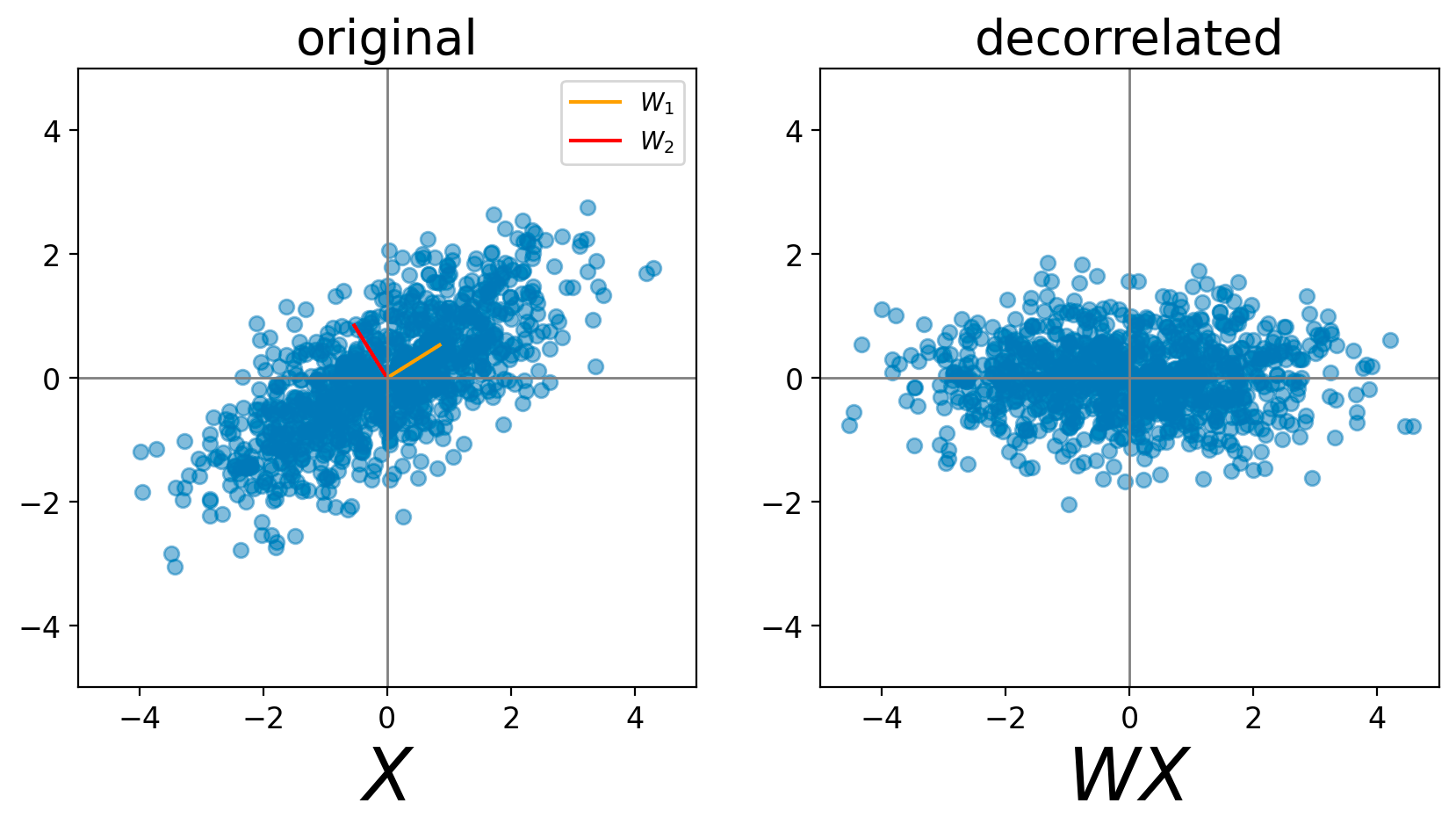
What’s lesser-known is not PCA itself, but the fact that it can be implemented by a neural network using a local update rule called Hebbian learning, or colloquially, the concept that “neurons that fire together wire together”. Let’s assume a simple linear model with some synaptic weight. If two connected neurons fire in response to the same input, then they likely represent some correlation, and Hebbian learning says we increase the strength of the connection.

In 1982, Erkki Oja proposed an implementation of PCA using Hebbian learning, and Terence Sanger generalized this in 1989 for a network with multiple output units. Given a linear neuron
Oja’s learning rule is
where η is the learning rate. The first term in the parentheses tells us that w_i grows proportionally with the correlation between the unit’s output y and input x_i, which is just Hebb’s rule. The second term constrains the growth of w_i (specifically, to be unit norm).
This implements learning the first principle component in PCA. How? If you let a linear neuron follow Hebb’s rule, you can show that the weight vector w_i will grow in the direction of the first eigenvector of the data’s covariance matrix, AKA the first principal component. The problem is that the length of w_i will grow exponentially, which is why Oja’s rule has the second term.
Sanger’s learning generalizes this to a network with multiple output neurons, i.e. multiple dimensions of PCA.

The first term below says we update weight ij proportionally with the correlation between input x_j and output y_i. The second term constrains the growth of w relative to other neurons’ correlations with the output.
I skipped over a ton of details, which you can read in Bruno’s explanation of the derivation here.
If we had a group of neurons implementing PCA, what would be the limitations of this representation? First, suppose we had datasets that had the same mean and variance in each dimension, but one had a Gaussian distribution while the other didn’t. PCA would arrive at the same solution for both datasets, because it considers only pairwise correlations, and produces orthogonal weights.

Unfortunately, most interesting problems are probably non-Gaussian. You’re probably starting to notice a theme: these models make a ton of simplifications, such as supervision, linear neurons, or Gaussian data. We must understand the limitations imposed by these assumptions, but we’ve got to start somewhere. We’d be in trouble if we couldn’t model Gaussian data!
We’ll continue in the next post with nonlinear learning strategies and their resulting representations: clustering and sparse coding.
The Transmitter has a couple of high-level articles discussing what the term representation actually refers to. Unsurprisingly, there’s no canonical definition.
AKA “AI”, if you have the right conflict of interests.
This is a bit contentious, but some believe backpropagation happens in some form in the brain. An example is this paper from Blake Richards and many others.
von Neumann cited them in the first draft of the EDVAC report.